

共有 7 個文件被更改,包括 0 次插入 和 931 次删除
分割檢視
Diff Options
-
+0 -11src/doc/book.asciidoc
-
+0 -176src/doc/callgrind.asciidoc
-
+0 -82src/doc/flame.asciidoc
-
+0 -41src/doc/introduction.asciidoc
-
+0 -254src/doc/messages.asciidoc
-
二進制src/doc/seq.png
-
+0 -367src/doc/tracing.asciidoc
+ 0
- 11
src/doc/book.asciidoc
查看文件
| @ -1,11 +0,0 @@ | |||
| = Looking Glass User Guide | |||
| include::introduction.asciidoc[Introduction] | |||
| include::tracing.asciidoc[Tracing] | |||
| include::callgrind.asciidoc[Callgrind profiling] | |||
| include::flame.asciidoc[Flame graph profiling] | |||
| include::messages.asciidoc[Messages profiling] | |||
+ 0
- 176
src/doc/callgrind.asciidoc
查看文件
| @ -1,176 +0,0 @@ | |||
| [[callgrind]] | |||
| == Callgrind profiling | |||
| Looking Glass' primary purpose is the profiling of | |||
| Erlang applications. This is done by first tracing | |||
| events to a file or socket and then processing it | |||
| to extract useful output. | |||
| Profiling tools generally have a few different types | |||
| of output. This chapter is about callgrind output, | |||
| which can be read using the `qcachegrind`/`kcachegrind` | |||
| tool. | |||
| === Quick start | |||
| Assuming you generated trace files using the profile | |||
| mode and the running flag, as detailed in the | |||
| xref:tracing_running[Tracing chapter], you can | |||
| generate callgrind.out files using the following | |||
| command: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile_many("traces.lz4.*", "callgrind.out", | |||
| #{running => true}). | |||
| ---- | |||
| This will create a callgrind.out file for all trace files | |||
| you generated. For example if you had 'traces.lz4.1' and | |||
| 'traces.lz4.2', you should now also have 'callgrind.out.1' | |||
| and 'callgrind.out.2'. | |||
| You can now open these two files in the cachegrind tool, | |||
| either from the user interface or from the command line: | |||
| [source,bash] | |||
| ---- | |||
| $ qcachegrind callgrind.out | |||
| ---- | |||
| It will automatically detect and open all files matching | |||
| the `callgrind.out.*` pattern. | |||
| === Profiling one file | |||
| You can profile one file by calling the function | |||
| `lg_callgrind:profile/2,3`. It takes the trace file name, | |||
| the output file name and an optional map of options: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile("traces.lz4.1", "callgrind.out.1"). | |||
| ---- | |||
| It also accepts options: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile("traces.lz4.1", "callgrind.out.1", | |||
| #{running => true}). | |||
| ---- | |||
| === Profiling many files | |||
| A convenience function is available for profiling many | |||
| files at once: `lg_callgrind:profile_many/2,3`. It takes | |||
| a wildcard pattern as first argument and a file name | |||
| prefix as second argument: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile_many("traces.lz4.*", "callgrind.out"). | |||
| ---- | |||
| If there were two trace files, this will result in two | |||
| 'callgrind.out' files: 'callgrind.out.1' and 'callgrind.out.2'. | |||
| It also accepts options: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile_many("traces.lz4.*", "callgrind.out", | |||
| #{running => true}). | |||
| ---- | |||
| === Running information | |||
| When the trace files contain running information, meaning | |||
| they were created with the `running` flag enabled, you | |||
| need to also pass the `running` flag to the profiler in | |||
| order to have that information available in 'callgrind.out' | |||
| files: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile_many("traces.lz4.*", "callgrind.out", | |||
| #{running => true}). | |||
| ---- | |||
| === Scope | |||
| By default the scope of the trace events is global. This | |||
| means that the cachegrind tool will group all events | |||
| together regardless of where they happened. This is | |||
| useful to see which functions take the most resources | |||
| overall. | |||
| Other times you may want to see which *processes* take | |||
| the most resources. To do this you need to instruct | |||
| Looking Glass to keep the process information when | |||
| generating the 'callgrind.out' files. This is done | |||
| using the `scope` option: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_callgrind:profile_many("traces.lz4.*", "callgrind.out", | |||
| #{scope => per_process}). | |||
| ---- | |||
| === Using the cachegrind tool | |||
| There are a few gotchas to be aware of when using the | |||
| cachegrind tool with the output generated by Looking Glass. | |||
| The cachegrind tool was built with imperative code in mind. | |||
| It does not deal too well with recursion. This means that | |||
| the number of times functions are called might not always | |||
| be correct, especially for functions that call themselves. | |||
| You can see an example of this issue when looking at the | |||
| call graph, for example. | |||
| Looking Glass uses ELF Object field for storing the pid of | |||
| the process when the `scope => per_process` option is used. | |||
| This allows you to investigate processes individually by | |||
| using the 'grouping' feature and selecting 'ELF Object'. | |||
| You can then see which processes take the most resources | |||
| and look at the function calls within those processes. | |||
| When the running flag is used, the following event types | |||
| are generated: | |||
| * Total time in microseconds | |||
| * Active time in microseconds | |||
| * Wait time in microseconds (scheduled out) | |||
| * Number of times the process was scheduled out | |||
| The following formula is true: `Total = Active + Wait`. | |||
| The wait time is the time spent when the process was | |||
| scheduled out, in other words it was not running. This | |||
| happens in a number of different places, like receive | |||
| clauses or when the reduction count reached zero. | |||
| The number of times the process was scheduled out may | |||
| or may not be accurate at this time. Another part that | |||
| may not be accurate is the time spent doing port | |||
| operations which may appear as active time when the | |||
| process is mostly waiting. Both will be improved | |||
| in the future. | |||
| While Looking Glass provides line number information | |||
| about the various calls, it is not able to identify | |||
| which function clause was involved during this call. | |||
| This means that the call information for functions | |||
| with a lot of clauses will get aggregated at the same | |||
| line number when looking at the source code in the | |||
| cachegrind tool. This has an important impact on | |||
| most standard behaviors, including `handle_event` | |||
| from `gen_statem`. You can however structure your | |||
| code so that clause-heavy functions only dispatch | |||
| to other functions, in turn getting a better view | |||
| in the cachegrind tool. | |||
| Looking Glass is not able to find the line number | |||
| of list comprehensions and funs at this time. They | |||
| will always point to line number 1. | |||
+ 0
- 82
src/doc/flame.asciidoc
查看文件
| @ -1,82 +0,0 @@ | |||
| [[flame]] | |||
| == Flame graph profiling | |||
| As an alternative to xref:callgrind[Callgrind output], | |||
| Looking Glass provides flame graphs. Flame graphs are | |||
| a graphical view of stack traces that make it obvious | |||
| where the most time is spent. It complements the other | |||
| graphical views provided by `qcachegrind`. | |||
| Looking Glass only takes care of providing an output | |||
| that can then be converted into a flame graph using | |||
| the usual tool (not included). This chapter will | |||
| explain both operations. | |||
| === Required trace options | |||
| In order to generate a flame graph we currently need to | |||
| use one additional option when tracing. This option will | |||
| result in adding stack trace information to call events. | |||
| The option is `process_dump` and it must be set to `true`. | |||
| To give an example, instead of this: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, "traces.lz4"). | |||
| ---- | |||
| Do this: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, "traces.lz4", | |||
| #{process_dump => true}). | |||
| ---- | |||
| === Profiling one file | |||
| The `lg_flame` module provides a similar interface as other | |||
| Looking Glass profilers. You can produce an intermediate | |||
| output based on one or many files. | |||
| To profile one file: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_flame:profile("traces.lz4.1", "output"). | |||
| ---- | |||
| This will create an intermediate file named 'output'. | |||
| === Profiling many files | |||
| To profile many files: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_flame:profile_many("traces.lz4.*", "output"). | |||
| ---- | |||
| Note that the output is always a single file as the | |||
| results are merged together. | |||
| === Building the flame graph | |||
| https://github.com/brendangregg/FlameGraph[flamegraph.pl] | |||
| can be used to produce actual SVG flame graphs. | |||
| First we need to clone it. Anywhere will do: | |||
| [source,bash] | |||
| $ git clone https://github.com/brendangregg/FlameGraph | |||
| Then we can use it on our output file to create an SVG: | |||
| [source,bash] | |||
| $ ./FlameGraph/flamegraph.pl output > output.svg | |||
| You can then open the output SVG in your Web browser | |||
| of choice. The produced SVG is interactive, you can | |||
| click on the different functions to zoom in, and you | |||
| can also search for a specific function call. | |||
+ 0
- 41
src/doc/introduction.asciidoc
查看文件
| @ -1,41 +0,0 @@ | |||
| [[introduction]] | |||
| == Introduction | |||
| Looking Glass is a tracer and profiler for Erlang/OTP. | |||
| Looking Glass is the next generation profiling tool. It | |||
| is implemented as an `erl_tracer` NIF and thus requires | |||
| Erlang/OTP 19.0 or above. | |||
| Looking Glass aims to provide a very efficient tool | |||
| usable both in development and production settings, | |||
| and capable of running for a very long amount of time | |||
| even on busy systems. | |||
| === Supported platforms | |||
| Looking Glass is currently developed on Linux but should | |||
| also work on OSX and Windows. | |||
| Looking Glass requires Erlang/OTP 19.0 or above. | |||
| A cachegrind tool is required for reading the output | |||
| from `lg_callgrind`. The `qcachegrind` tool (also | |||
| known as `kcachegrind`) is recommended. Note that | |||
| it is a good idea to also install `graphviz` to | |||
| have the quite informative call graphs. | |||
| === Requirements | |||
| Looking Glass requires a C compiler toolchain and an `lz4` library to be installed. | |||
| === License | |||
| Looking Glass is double-licensed under the Mozilla | |||
| Public License 1.1 and the Apache License version 2. | |||
| See the LICENSE file for more information. | |||
| === Versioning | |||
| Looking Glass uses https://semver.org/[Semantic Versioning 2.0.0]. | |||
+ 0
- 254
src/doc/messages.asciidoc
查看文件
| @ -1,254 +0,0 @@ | |||
| [[messages]] | |||
| == Messages profiling | |||
| Looking Glass can also be used to profile Erlang processes | |||
| based on the messages they send. It can help you detect | |||
| which processes are the most busy and is able to generate | |||
| graphs and sequence diagrams to help you debug complex | |||
| issues. | |||
| === Enabling the tracing of messages | |||
| By default Looking Glass will not include the messages | |||
| in the trace files. It needs to be enabled through the | |||
| xref:tracing_send[send option]. | |||
| The output from one tracing session can then be used | |||
| for both callgrind and message profiling. | |||
| === Profiling one file | |||
| You can profile one file by calling the function | |||
| `lg_messages:profile/1`. It takes the trace file name | |||
| and prints out the result of the profiling. | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_messages:profile("traces.lz4.1"). | |||
| ---- | |||
| It will also create a GraphViz file currently hardcoded as | |||
| 'digraph.gv' and print further instructions to use it. | |||
| === Profiling many files | |||
| A convenience function is available for profiling many | |||
| files at once: `lg_callgrind:profile_many/2,3`. It takes | |||
| a wildcard pattern as first argument and a file name | |||
| prefix as second argument: | |||
| You can profile many files by calling the function | |||
| `lg_messages:profile_many/1`. It takes a wildcard pattern | |||
| and prints out the result of the profiling. The result | |||
| is a merge of the events in the different trace files. | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_messages:profile_many("traces.lz4.*"). | |||
| ---- | |||
| === Profile output | |||
| The profile step will result in four tables being printed. | |||
| * The first table shows the processes that sent the most messages. | |||
| * The second table shows the processes that sent the most messages | |||
| to processes that are either dead or never existed in the first place. | |||
| * The third table shows the processes that were most frequently sending | |||
| messages to one specific other process (from Alice to Bob). | |||
| * The last table shows the processes that were exchanging the most | |||
| messages (from Alice to Bob, and from Bob to Alice). | |||
| .Example output | |||
| ---- | |||
| 1> lg_messages:profile_many("traces.lz4.*"). | |||
| They sent the most messages | |||
| =========================== | |||
| Process ID Count Most recent message | |||
| ---------- ----- ------------------- | |||
| <7782.367.0> 147327 {notify,{event,channel_closed,...}} | |||
| <7782.356.0> 73035 {notify,{event,connection_closed,...}} | |||
| <7782.382.0> 30514 pause | |||
| <7782.391.0> 30052 {'$gen_cast',{deliver,{...},...}} | |||
| <7782.365.0> 1486 {channel_exit,1,{writer,...}} | |||
| [...] | |||
| They sent the most messages to dead processes | |||
| ============================================= | |||
| Process ID Count Most recent message | |||
| ---------- ----- ------------------- | |||
| <7782.367.0> 29 {notify,{event,channel_closed,...}} | |||
| They sent the most messages to one other process | |||
| ================================================ | |||
| From pid To pid Count Most recent message | |||
| -------- ------ ----- ------------------- | |||
| <7782.367.0> <7782.365.0> 74318 {notify,{event,channel_closed,...}} | |||
| <7782.356.0> <7782.367.0> 73001 {notify,{event,connection_closed,...}} | |||
| <7782.367.0> <7782.375.0> 73000 {notify,{event,channel_closed,...}} | |||
| <7782.382.0> <7782.391.0> 30202 pause | |||
| <7782.391.0> <7782.375.0> 29894 {'$gen_cast',{deliver,{...},...}} | |||
| <7782.365.0> <7782.375.0> 1485 {channel_exit,1,{writer,...}} | |||
| [...] | |||
| They sent the most messages to each other | |||
| ========================================= | |||
| Count Pid 1 Most recent message | |||
| Pid 2 from the corresponding process | |||
| ----- ----- ------------------------------ | |||
| 74318 <7782.365.0> {channel_exit,1,{writer,...}} | |||
| <7782.367.0> {notify,{event,channel_closed,...}} | |||
| 73001 <7782.356.0> {notify,{event,connection_closed,...}} | |||
| <7782.367.0> {notify,{event,channel_closed,...}} | |||
| 73000 <7782.367.0> {notify,{event,channel_closed,...}} | |||
| <7782.375.0> '<none>' | |||
| 30351 <7782.382.0> pause | |||
| <7782.391.0> {'$gen_cast',{deliver,{...},...}} | |||
| 29894 <7782.375.0> '<none>' | |||
| <7782.391.0> {'$gen_cast',{deliver,{...},...}} | |||
| [...] | |||
| The file digraph.gv was created. Use GraphViz to make a PNG. | |||
| $ dot -Tpng -O digraph.gv | |||
| You can also edit the file to remove uninteresting processes. | |||
| One line in the file is equal to a connection between two processes. | |||
| ---- | |||
| At the end of the output, instructions are given to generate an | |||
| image from a GraphViz file. This image shows the relationships | |||
| between the processes and indicates how many messages they send | |||
| to each other. | |||
| The file generated by Looking Glass is a text file that can be | |||
| further edited as necessary. It looks like this: | |||
| ---- | |||
| digraph { | |||
| concentrate=true; | |||
| splines=ortho; | |||
| edge [arrowhead=none, labelfontsize=12.0, minlen=3]; | |||
| "error_logger" -> "<7782.354.0>" [taillabel=0, headlabel=2]; | |||
| "<7782.32.0>" -> "<7782.380.0>" [taillabel=0, headlabel=1]; | |||
| "<7782.388.0>" -> "<7782.391.0>" [taillabel=0, headlabel=1]; | |||
| "error_logger" -> "<7782.355.0>" [taillabel=0, headlabel=4]; | |||
| [...] | |||
| } | |||
| ---- | |||
| It is of course possible to edit this file. You may want to | |||
| modify the style attributes, or even remove processes from | |||
| the output entirely. | |||
| === Generating sequence diagrams | |||
| Looking Glass can also be used to extract the sequence of messages | |||
| exchanged between two or more processes. This is done using the | |||
| `lg_messages_seqdiag` module, which works just like `lg_messages` | |||
| ecept the functions take a second argument containing the list of | |||
| pids you wish to investigate. | |||
| To look at one file: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_messages_seqdiag:profile("traces.lz4.1", | |||
| ["<7788.381.0>", "<7788.382.0>", "<7774.383.0>", | |||
| "<7774.384.0>", "<7774.386.0>"]). | |||
| ---- | |||
| And many files: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg_messages_seqdiag:profile_many("traces.lz4.*", | |||
| ["<7788.381.0>", "<7788.382.0>", "<7774.383.0>", | |||
| "<7774.384.0>", "<7774.386.0>"]). | |||
| ---- | |||
| The list of pids must be given as a list of strings. This is | |||
| because the processes represented do not exist on the running | |||
| system. Looking Glass will ignore the node information from the | |||
| pid too, so you do not need to worry about it. This explains why | |||
| the pids requested in the previous two snippets look as if they | |||
| come from different nodes. The pids `"<7888.381.0>"` and | |||
| `"<7774.381.0>"` are therefore equivalent. | |||
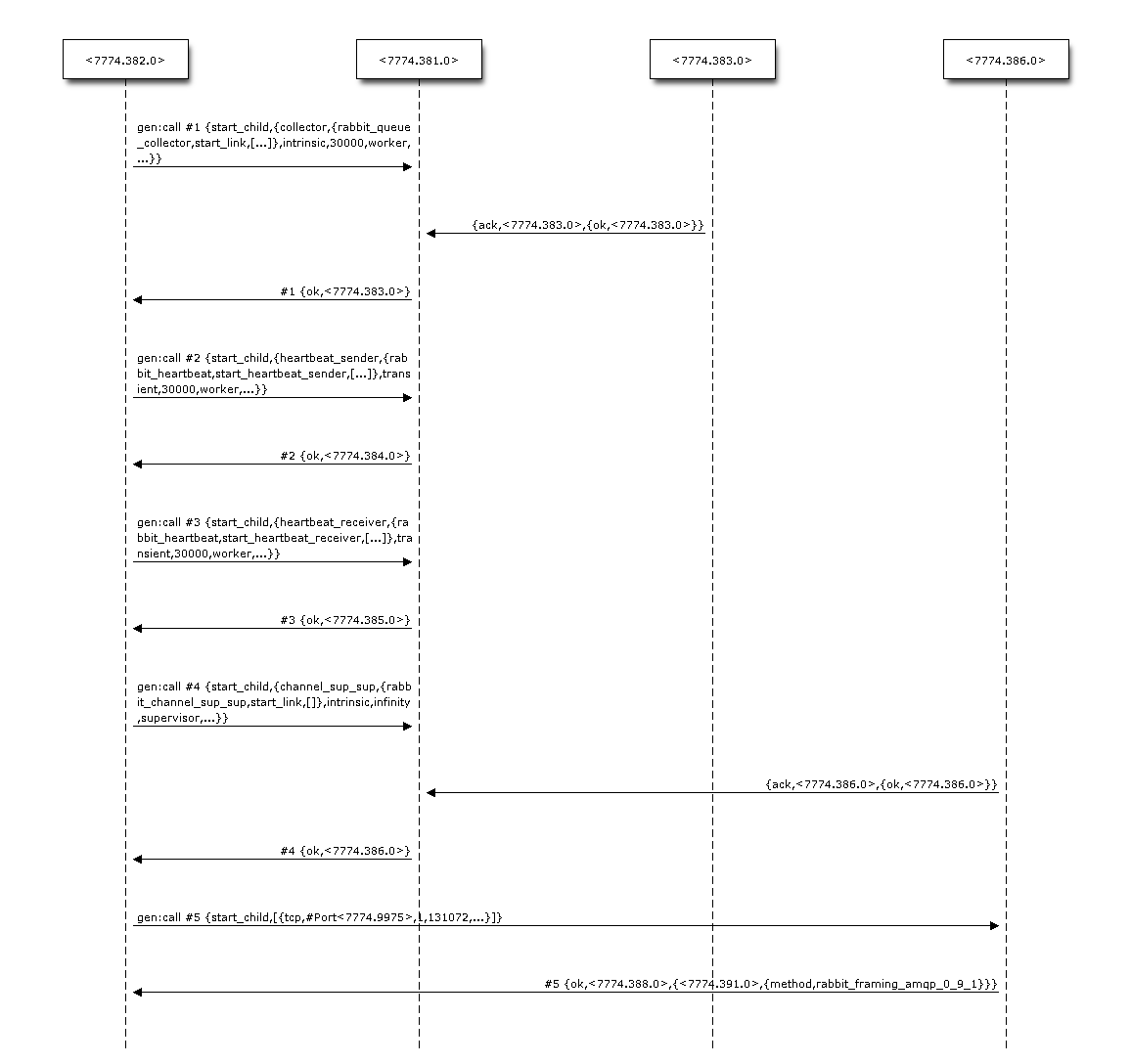
| After running one of these commands, you will end up with a | |||
| file 'seq.diag' that can then be used to create an image. This | |||
| file can also be edited later on if necessary. It looks like this: | |||
| ---- | |||
| seqdiag { | |||
| edge_length = 300; | |||
| activation = none; | |||
| "<7774.382.0>" -> "<7774.381.0>" [label="gen:call #1 {start_child,{collector,{rabbit_queue_collector,start_link,[...]},intrinsic,30000,worker,...}}"]; | |||
| "<7774.383.0>" -> "<7774.381.0>" [label="{ack,<7774.383.0>,{ok,<7774.383.0>}}"]; | |||
| "<7774.381.0>" -> "<7774.382.0>" [label="#1 {ok,<7774.383.0>}"]; | |||
| [...] | |||
| } | |||
| ---- | |||
| Before you can create an image from it, you will need to install | |||
| `seqdiag`. Installation instructions will depend on your system. | |||
| The project page is at http://blockdiag.com/en/seqdiag/ | |||
| .Example output | |||
| image::seq.png[] | |||
| === Identifying processes | |||
| While Looking Glass will display the pid and one sample message | |||
| from each process, it's not always ideal to identify which process | |||
| is which. | |||
| To allievate that, Looking Glass offers a simple solution: | |||
| sending a message to the named process `lg` while a tracer is | |||
| running. Looking Glass will inevitably log this message in the | |||
| trace file, recognize that the target is `lg` and use the | |||
| message as metadata. This metadata is then available to any | |||
| module reading from the trace file. | |||
| The process is only available when Looking Glass is running, | |||
| of course, which means we can't just send a message directly. | |||
| The following works: | |||
| [source,erlang] | |||
| ---- | |||
| is_pid(whereis(lg)) andalso (lg ! Info). | |||
| ---- | |||
| This can be made into a macro, of course: | |||
| [source,erlang] | |||
| ---- | |||
| %% Store metadata in the trace files when message tracing is enabled. | |||
| -define(LG_INFO(Info), is_pid(whereis(lg)) andalso (lg ! Info)). | |||
| ---- | |||
| And can then be used like this: | |||
| [source,erlang] | |||
| ---- | |||
| ?LG_INFO(#{process_type => reader}). | |||
| ---- | |||
| The message must always be a map. Reading the trace file | |||
| will otherwise fail. Looking Glass only recognizes the | |||
| `process_type` field, and uses it as a label to identify | |||
| processes when profiling exchanges of messages. You are | |||
| free to define any other value you need in the map. | |||
| The metadata can also be updated by sending another message | |||
| or by calling the macro a second time. The operation done | |||
| on the map will be a merge by default. | |||
二進制
src/doc/seq.png
查看文件
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1156 | Height: 1088 | Size: 18 KiB |
+ 0
- 367
src/doc/tracing.asciidoc
查看文件
| @ -1,367 +0,0 @@ | |||
| [[tracing]] | |||
| == Tracing | |||
| Looking Glass is both a tracing and a profiling tool. | |||
| In this chapter we will take a look at the tracing | |||
| capabilities of the tool, and also learn how to create | |||
| trace files which are necessary for profiling. | |||
| === First steps | |||
| Let's start by tracing everything. | |||
| Open an Erlang shell and run the following command: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_'). | |||
| {link,<0.4.0>,1488297881224444,#Port<0.692>} | |||
| {getting_unlinked,<0.4.0>,1488297881224533,#Port<0.692>} | |||
| {link,<0.4.0>,1488297881224640,#Port<0.693>} | |||
| {getting_unlinked,<0.4.0>,1488297881224720,#Port<0.693>} | |||
| {link,<0.4.0>,1488297881224817,#Port<0.694>} | |||
| {getting_unlinked,<0.4.0>,1488297881224881,#Port<0.694>} | |||
| {link,<0.4.0>,1488297881224979,#Port<0.695>} | |||
| {getting_unlinked,<0.4.0>,1488297881225060,#Port<0.695>} | |||
| ... | |||
| ---- | |||
| As you can see we get a lot of output. That's because | |||
| the `lg:trace/1` function will by default output the | |||
| raw trace events to the console. We also used the atom | |||
| `'_'` to tell Looking Glass to trace all modules, and | |||
| didn't restrict which process should be traced. | |||
| Needless to say, do not do this in production. | |||
| The trace events always come with an event name, the pid | |||
| of the process where the event happened, a timestamp in | |||
| microseconds and one or two extra elements providing | |||
| extra context about the event. | |||
| For example the following event is a function call occuring | |||
| in the process `<0.64.0>` at timestamp `1488297891226328` | |||
| to `supervisor:handle_info/2`. | |||
| [source,erlang] | |||
| ---- | |||
| {call,<0.64.0>,1488297891226328,{supervisor,handle_info,2}} | |||
| ---- | |||
| === Stop tracing | |||
| To stop tracing, simply call: | |||
| [source,erlang] | |||
| ---- | |||
| 2> lg:stop(). | |||
| ---- | |||
| === Tracing specific modules | |||
| In order to get a more interesting output we need to filter | |||
| what will be traced. We may for example only want the events | |||
| from the module `shell`: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace(shell). | |||
| ... | |||
| {call,<0.58.0>,1488298545020494,{shell,result_will_be_saved,0}} | |||
| {call,<0.58.0>,1488298545020497,{shell,get_history_and_results,0}} | |||
| {call,<0.58.0>,1488298545020498,{shell,get_env,2}} | |||
| {return_to,<0.58.0>,1488298545020501,{shell,get_history_and_results,0}} | |||
| {call,<0.58.0>,1488298545020502,{shell,get_env,2}} | |||
| {return_to,<0.58.0>,1488298545020503,{shell,get_history_and_results,0}} | |||
| {return_to,<0.58.0>,1488298545020504,{shell,result_will_be_saved,0}} | |||
| ... | |||
| ---- | |||
| We can also request to trace a list of modules: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace([shell, user_drv]). | |||
| ... | |||
| {call,<0.58.0>,1488299067458321,{shell,record_print_fun,1}} | |||
| {return_to,<0.58.0>,1488299067458322,{shell,pp,4}} | |||
| {call,<0.58.0>,1488299067458323,{shell,enc,0}} | |||
| {call,<0.49.0>,1488299067459603,{user_drv,handle_req,4}} | |||
| {call,<0.49.0>,1488299067459605,{user_drv,get_unicode_state,1}} | |||
| ... | |||
| ---- | |||
| === Tracing applications | |||
| In addition to providing modules, you can provide OTP applications. | |||
| When you do so all the modules belonging to the application will | |||
| be traced. We can of course trace Looking Glass itself: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace({app, looking_glass}). | |||
| {link,<0.4.0>,1488299179652509,#Port<0.688>} | |||
| {getting_unlinked,<0.4.0>,1488299179652621,#Port<0.688>} | |||
| {call,<0.58.0>,1488299179653161,{lg,'-trace_patterns/1-fun-0-',1}} | |||
| {call,<0.58.0>,1488299179653164,{lg,trace_pattern,1}} | |||
| ... | |||
| ---- | |||
| Note that Looking Glass will disable tracing on the tracer processes | |||
| themselves (to avoid an infinite recursion). More on that later. | |||
| You can trace any combination of modules and applications: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace([shell, {app, looking_glass}]). | |||
| ... | |||
| ---- | |||
| === Tracing specific processes | |||
| Looking Glass traces all processes by default. | |||
| Large systems tend to have many processes and this can generate | |||
| a lot of noise, especially if you are trying to optimize a | |||
| specific component. | |||
| You can specify which processes should be traced using the | |||
| input option `scope`: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace([{scope, [self()]}, io]). | |||
| {call,<0.58.0>,1489494935163831,{io,columns,0}} | |||
| {call,<0.58.0>,1489494935163841,{io,default_output,0}} | |||
| {return_to,<0.58.0>,1489494935163844,{io,columns,0}} | |||
| {call,<0.58.0>,1489494935163846,{io,columns,1}} | |||
| ... | |||
| ---- | |||
| The list found in the `scope` tuple can take the same values | |||
| as the first argument to `erlang:trace/3`. When the tuple is | |||
| missing the default will be `processes`. | |||
| The scope tuple can be found multiple time in the input. | |||
| This is particularly useful when combining trace definition | |||
| callbacks. | |||
| Looking Glass will trace all the processes specified but | |||
| also the processes that they create. This means that when | |||
| you provide a supervisor pid, all its children will also | |||
| be traced, as long as they were started after the start | |||
| of the trace session. | |||
| === Trace definition callbacks | |||
| For ease of use, Looking Glass allows you to define functions in | |||
| your code that return interesting patterns. This allows you to | |||
| define areas of your code that you profile often, or to dynamically | |||
| generate the list if necessary. | |||
| To use callbacks, simply provide a callback tuple: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace({callback, lg_callgrind, patterns}). | |||
| ---- | |||
| You can of course use it in combination with other inputs: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace([shell, {callback, lg_callgrind, patterns}]). | |||
| ---- | |||
| You can also combine as many callbacks as you wish. | |||
| The callback takes the following form: | |||
| [source,erlang] | |||
| ---- | |||
| patterns() -> lg:input(). | |||
| ---- | |||
| The function name can be anything. A module may have more than one | |||
| Looking Glass callback. | |||
| The return value is a list of patterns and scopes that will | |||
| be traced. It can therefore contain modules, applications | |||
| or other callbacks. | |||
| An example callback could be: | |||
| [source,erlang] | |||
| ---- | |||
| -module(ranch_lg). | |||
| -export([connections/0]). | |||
| %% Trace all events but only from the TCP connection processes. | |||
| connections() -> | |||
| ConnsPid = ranch_server:get_connections_sup(tcp_echo), | |||
| ['_', {scope, [ConnsPid]}]. | |||
| ---- | |||
| === Tracers | |||
| Looking Glass comes with a number of tracers. The default is called | |||
| `lg_raw_console_tracer` and simply outputs the events to the console, | |||
| without any formatting applied. | |||
| The default `lg:trace/1` call is equivalent to the following: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace(shell, lg_raw_console_tracer, undefined, #{}). | |||
| ---- | |||
| The arguments are, in order, the trace patterns (the modules or | |||
| applications that need to be traced), the tracer module, the tracer | |||
| options, and the Looking Glass options. | |||
| === Tracing to file | |||
| Looking Glass comes with a tracer that saves all events directly | |||
| into a compressed file. Trace files can be used for replaying events | |||
| (for example if you're looking for something specific when debugging) | |||
| or for profiling. | |||
| Looking Glass compresses the trace files using the LZ4 compression | |||
| algorithm. This algorithm was chosen for its very low footprint; | |||
| it allows us to reduce the trace file size without putting a strain | |||
| on the system being traced. The files produced are compatible with | |||
| the LZ4 command line tools. | |||
| The options for this tracer are only the filename: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, "traces.lz4"). | |||
| ---- | |||
| If you play with the shell a little after running this command, | |||
| and then run `lg:stop().` you can see that the following files | |||
| have been created: | |||
| [source,bash] | |||
| ---- | |||
| $ ls -l traces.lz4.* | |||
| -rw-r--r-- 1 essen essen 333676 Feb 28 18:24 traces.lz4.1 | |||
| -rw-r--r-- 1 essen essen 384471 Feb 28 18:24 traces.lz4.2 | |||
| -rw-r--r-- 1 essen essen 333776 Feb 28 18:24 traces.lz4.3 | |||
| -rw-r--r-- 1 essen essen 11689 Feb 28 18:24 traces.lz4.4 | |||
| ---- | |||
| Looking Glass will create one trace file per scheduler by | |||
| default (which is typically equal to the number of cores | |||
| you have on your machine). The files are split so that | |||
| all the events of one process are always stored in the | |||
| same file. | |||
| We can use the file reader module coming with Looking Glass | |||
| to inspect the contents of the files: | |||
| [source,erlang] | |||
| ---- | |||
| 2> lg_file_reader:foreach(fun(E) -> erlang:display(E) end, "traces.lz4.1"). | |||
| {call,<0.51.0>,1488302656982110,{group,io_request,5}} | |||
| {call,<0.51.0>,1488302656982114,{group,io_request,4}} | |||
| {call,<0.51.0>,1488302656982117,{group,get_tty_geometry,1}} | |||
| {call,<0.75.0>,1488302656982129,{file_io_server,io_request,2}} | |||
| ... | |||
| ---- | |||
| Careful though, don't run this on production either! | |||
| Trace files can become really, really big. | |||
| You may also write a slightly larger fun to filter what | |||
| you want to see, for example all events from a single | |||
| process: | |||
| [source,erlang] | |||
| ---- | |||
| 3> Pid = pid(0,51,0). | |||
| <0.51.0> | |||
| 4> F = fun(E) when element(2, E) =:= Pid -> | |||
| erlang:display(E); | |||
| (_) -> | |||
| ok | |||
| end. | |||
| #Fun<erl_eval.6.52032458> | |||
| 5> lg_file_reader:foreach(F, "traces.lz4.1"). | |||
| {call,<0.51.0>,1488302656982110,{group,io_request,5}} | |||
| {call,<0.51.0>,1488302656982114,{group,io_request,4}} | |||
| {call,<0.51.0>,1488302656982117,{group,get_tty_geometry,1}} | |||
| {return_to,<0.51.0>,1488302656982306,{group,io_request,4}} | |||
| ... | |||
| ---- | |||
| === Tracer mode | |||
| When tracing to file for the purposes of profiling, you | |||
| most likely do not care about certain events, like processes | |||
| being linked. To disable any unnecessary event for profiling, | |||
| pass the `mode` option: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, "traces.lz4", #{mode => profile}). | |||
| ---- | |||
| [[tracing_running]] | |||
| You can also get extra events that are only useful for profiling | |||
| by enabling options. The `running` option will enable events | |||
| indicating when processes are scheduled in or out. It's generally | |||
| useful to have as it enables additional stats, but can take a lot | |||
| of resources and so isn't enabled by default: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, "traces.lz4", | |||
| #{mode => profile, running => true}). | |||
| ---- | |||
| [[tracing_send]] | |||
| You may want to also trace the messages sent by the processes. | |||
| To do so you need to enable the `send` option. You can then | |||
| xref:messages[obtain detailed information about the processes | |||
| sending messages]. To enable the tracing of messages: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, "traces.lz4", | |||
| #{send => true}). | |||
| ---- | |||
| All the options in this section can be combined at will. It is | |||
| possible to use the data from the same tracing session when | |||
| profiling both functions and messages. | |||
| === Trace file rotation | |||
| For long running sessions Looking Glass can rotate trace files. | |||
| This is a feature that helps avoid running out of disk space | |||
| and is not meant to be for keeping files small (Looking Glass | |||
| can deal with very large files just fine). | |||
| Instead of passing a filename prefix as a third argument to | |||
| `lg:trace/3,4`, a map can be provided. There are currently | |||
| three options including the `filename_prefix`. The other options | |||
| are the maximum file size in bytes, `max_size`, and the number | |||
| of events that will be stored per LZ4 frame in the file, | |||
| `events_per_frame`. These two options allow you to control | |||
| how often the file will be written to or rotated. | |||
| The following example will limit the file sizes to 100MB: | |||
| [source,erlang] | |||
| ---- | |||
| 1> lg:trace('_', lg_file_tracer, | |||
| #{filename_prefix => "traces.lz4", max_size => 100000000}, | |||
| #{mode => profile, running => true}). | |||
| ---- | |||
| During testing of this feature it appeared that the rotation | |||
| as it's currently implemented is expensive, therefore you | |||
| should be careful not to put a value that's too low. | |||